7. Benutzerdefinierte Datentypen (UDTs)
Wenn die vorgegebenen Datentypen nicht ausreichen (und das ist in der fortgeschrittenen Programmierung sehr häufig der Fall), lassen sich eigene Datentypen definieren. Im Englischen spricht man von user defined types, kurz UDT. Ein UDT setzt sich, vereinfacht gesagt, aus mehreren Variablen bereits bekannter Datentypen zusammen. Auf diesen einfachen Fall wollen wir uns in diesem Kapitel beschränken. UDTs können aber deutlich mehr, als nur ein paar Variablen zusammenzufassen: Sie sind die Basis der objektorientierten Programmierung, die zu komplex ist, um sie in ein einziges Kapitel zu pressen, und die daher in einen eigenen Bereich des Buches besprochen wird.
7.1 Deklaration
Ein beliebtes Beispiel für die (hier behandelte vereinfachte) Verwendung eines UDTs ist ein Datentyp zur Speicherung von Adressen. Zu einer Adresse gehören unter anderem der Vorname, Nachname, Straßenname und Hausnummer, die Postleitzahl und der Wohnort. Diese sechs Angaben können selbstverständlich in sechs verschiedenen Variablen gespeichert werden, aber spätestens bei der gleichzeitigen Verwendung mehrerer Adressen wird das unangenehm. Stattdessen werden die Angaben jetzt in einem UDT zusammengefasst und sind dadurch leichter zu verwalten.
TYPE Adresse AS STRING vorname, nachname, strasse, ort AS INTEGER hausnummer, plz END TYPE
Der Quelltext-Ausschnitt legt einen neuen Datentyp mit dem Namen Adresse an, der ab sofort für die Deklaration neuer Variablen verwendet werden kann. Er beinhaltet sechs Mitglieder (engl.: member), die auch Attribute genannt werden.1 Auf die Attribute kann, sowohl lesend als auch schreibend, nach dem Muster udtname.attributname zugegriffen werden. Dazu folgt in Quelltext 7.1 ein Beispiel. Die Attribute, z. B. vorname, existieren nur innerhalb des UDTs, es wird also keine allgemein verfügbare Variable mit dem Namen vorname angelegt.
Ihnen wird sicher aufgefallen sein, dass die Deklaration der Attribute sehr ähnlich aussieht wie eine Variablendeklaration, nur dass das Schlüsselwort DIM nicht erforderlich ist (erlaubt ist es allerdings). Der UDT-Typname wird sehr oft groß geschrieben, um ihn optisch von einem Variablennamen abzuheben. Viele Programmierer kennzeichnen Typnamen auch durch ein Prefix, wie z. B. ein vorangestelltes Typ oder T. Der Typname würde dann TypAdresse oder TAdresse lauten.
' UDT deklarieren TYPE TAdresse AS STRING vorname, nachname, strasse, ort AS INTEGER hausnummer, plz END TYPE ' neue Adressenvariablen anlegen DIM AS TAdresse adresse1, adresse2 ' Werte zuweisen adresse1.vorname = "Simon" adresse1.nachname = "Mustermann" adresse2.vorname = "Sandra" ' Werte auslesen PRINT adresse1.vorname SLEEP
Der Vorteil eines UDTs wird auch in diesem kurzen Beispiel bereits deutlich. Für das komplette Set vorname, nachname usw. ist nur ein einziger Variablenname nötig. Statt für die beiden angelegten Adressen zwölf Variablen deklarieren zu müssen, reichen lediglich zwei. Außerdem besteht eine feste Zuordnung zwischen Vor- und Nachnamen derselben Adresse; sie können nicht versehentlich mit anderen Adressen vertauscht werden. Besonders interessant wird diese Zusammenlegung, wenn mit Arrays oder Parameterübergabe gearbeitet wird, doch dazu später mehr.
Für die Attribute können Sie jeden Datentyp verwenden, der dem Compiler zu diesem Zeitpunkt bekannt ist, d. h. also alle Standard-Datentypen und andere UDTs, die bereits deklariert wurden. Nicht möglich ist die Verwendung von UDTs, die erst später deklariert werden und die der Compiler daher zu diesem Zeitpunkt noch nicht kennt. Falls Sie so etwas benötigen, schafft das forward referencing Abhilfe; diese Methode werden wir aber erst in [KapOOPForward] behandeln.
Quelltext 7.2 zeigt die Einbindung eines bereits bekannten UDTs als Attribut-Datentyp. Dazu wird erst ein Datentyp für die Speicherung von Vor- und Nachnamen deklariert. Dieser kann anschließend im Adress-UDT verwendet werden.
' UDTs deklarieren TYPE TName AS STRING vorname, nachname END TYPE TYPE TAdresse AS TName name_ AS STRING strasse, ort AS INTEGER hausnummer, plz END TYPE ' Zugriff auf die Elemente DIM AS TAdresse adresse adresse.hausnummer = 32 adresse.name_.vorname = "Sonja" PRINT adresse.name_.vorname SLEEP
UDTs können beliebig ineinander verschachtelt werden, jedoch wird der Zugriff auf die Attribute durch die langen Bezeichnungsketten mühseliger. Den Namen in ein eigenes UDT auszulagern macht vor allem dann Sinn, wenn dieses UDT auch außerhalb des Adress-UDTs eine Bedeutung hat, z. B. weil auch Namen ohne zugehörige Adresse gespeichert werden müssen.
|
|
Hinweis:NAME ist ein FreeBASIC-Schlüsselwort und kann nicht als Variablenname verwendet werden. Viele Schlüsselwörter, darunter auch NAME, können jedoch als Bezeichnung für ein Mitglied eines UDTs verwendet werden, da sie innerhalb der UDT-Deklaration keine eigenständige Bedeutung besitzen. Dennoch wurde in Quelltext 7.2 die Variante mit dem abschließenden Unterstrich gewählt, die in keiner Situation ein Schlüsselwort ist. |
7.2 Mitgliederzugriff mit WITH
Ein einfacherer Zugriff auf die Mitglieder eines UDTs ist durch den WITH-Block möglich. Zusammen mit WITH wird der Name des UDTs angegeben, auf dessen Elemente zugegriffen werden soll. Beim Zugriff auf ein Mitglied dieses UDTs kann anschließend innerhalb des Blocks der UDT-Name weggelassen werden. Das Mitglied beginnt dann mit einem Punkt.
TYPE TAdresse AS STRING vorname, nachname, strasse, ort AS INTEGER hausnummer, plz END TYPE DIM AS TAdresse adresse1, adresse2 WITH adresse1 .strasse = "Einbahnstr." ' Kurzform von adresse1.strasse adresse2.strasse = "Milchstr." ' geht natuerlich immer noch .hausnummer = 39 ' Kurzform von adresse1.hausnummer END WITH
WITH-Blöcke können ineinander verschachtelt sein. Es gilt dann immer das UDT des innersten Blocks, in dem sich das Programm zur Zeit befindet. END WITH beendet den aktuellen WITH-Block.
TYPE TAdresse AS STRING vorname, nachname, strasse, ort AS INTEGER hausnummer, plz END TYPE DIM AS TAdresse adresse1, adresse2 WITH adresse1 ' Kurzschreibweisen beziehen sich jetzt auf adresse1 .strasse = "Einbahnstr." ' Kurzform von adresse1.strasse WITH adresse2 ' Kurzschreibweisen beziehen sich jetzt auf adresse2 .strasse = "Milchstr." ' Kurzform von adresse2.strasse END WITH ' Kurzschreibweisen beziehen sich wieder auf adresse1 .hausnummer = 39 ' Kurzform von adresse1.hausnummer END WITH
7.3 Speicherverwaltung
Die Speicherplätze für die Attribute eines UDTs liegen direkt hintereinander (ein weiterer Vorteil von UDTs, weil sie sich dadurch oft komplett an einem Stück speichern und laden lassen2 ). Die Speicherstellen werden in der Regel „dicht aneinander“ gepackt, wobei jedoch „Füllstellen“ freigelassen werden können, wenn dadurch ein einfacherer Speicherzugriff möglich wird. Man spricht hier vom Padding.
Besteht ein UDT aus drei BYTE-Attributen, so benötigt es drei Byte Speicherplatz. Besteht es jedoch aus einem BYTE und einem INTEGER, dann wäre es unpraktisch, den INTEGER-Wert direkt hinter das BYTE zu hängen. Ein INTEGER hat ja den Vorteil, dass es direkt in einem Arbeitsschritt gelesen bzw. geschrieben werden kann. Das funktioniert aber nicht, wenn sein Speicherbereich über die Grenze einer INTEGER-Speicherstelle hinausragt. An dieser Stelle kommt das Padding ins Spiel: Der Speicherbereich wird automatisch so ausgeweitet, dass ein schneller Datenzugriff ermöglicht wird. Allerdings können Sie dieses Verhalten auch beeinflussen.
|
|
Hinweis: Über Padding müssen Sie sich vorerst nur in drei Fällen Gedanken machen: • Sie arbeiten mit sehr großen Datenmengen und müssen auf den Speicherverbrauch achten, oder • Sie verwenden Datentypen aus anderen (Nicht-FreeBASIC-)Quellen, die ein anderes Padding verwenden als FreeBASIC, oder • Sie wollen nicht nur programmieren, sondern auch verstehen, was im Hintergrund passiert. Wenn mindestens einer der drei Fälle zutrifft, sollten Sie weiterlesen. Wenn nicht, können Sie diesen Abschnitt getrost überspringen, mit Kapitel 7.4 fortfahren und bei Bedarf auf diesen Abschnitt zurückkommen. |
Das Padding-Verhalten soll in Quelltext 7.5 veranschaulicht werden. Wir nutzen dazu zwei Funktionen: Mit SIZEOF() lässt sich die Speichergröße eines Elements ausgeben. Man kann damit die Anzahl der Bytes ausgeben lassen, die von einer angegebenen Variablen, aber auch von Variablen eines angegebenen Datentyps belegt werden. Um das Offset, also die Speicherposition eines Attributs relativ zu seinem UDT zu ermitteln, dient OFFSETOF(). Das erste Attribut, das in einer UDT-Definition angegeben wird, hat immer das Offset 0.
|
|
Achtung: Bei Strings variabler Länge beträgt die von SIZEOF() ausgegebene Speichergröße je nach Architektur immer 12 Byte (32-Bit-Rechner) oder 24 Byte (64-Bit-Rechner). Das entspricht der Größe des Headers, in dem u. a. auch die Position und Länge des Stringinhalts gespeichert wird. |
TYPE T1 AS BYTE b1, b2, b3 END TYPE TYPE T2 AS BYTE b1, b2 AS INTEGER i END TYPE TYPE T3 AS BYTE b1 AS INTEGER i AS BYTE b2 END TYPE PRINT "UDT", "SIZEOF", "Offset 1", "Offset 2", "Offset 3" PRINT "T1", SIZEOF(T1), OFFSETOF(T1, b1), OFFSETOF(T1, b2), OFFSETOF(T1, b3) PRINT "T2", SIZEOF(T2), OFFSETOF(T2, b1), OFFSETOF(T2, b2), OFFSETOF(T2, i) PRINT "T3", SIZEOF(T3), OFFSETOF(T3, b1), OFFSETOF(T3, i), OFFSETOF(T3, b2) SLEEP
UDT SIZEOF Offset 1 Offset 2 Offset 3
T1 3 0 1 2
T2 8 0 1 4
T3 12 0 4 8Diese Ausgabe gilt für die 32-Bit-Version des Compilers. Wie die Speicherbelegung zustande kommt, lässt sich schematisch folgendermaßen darstellen:
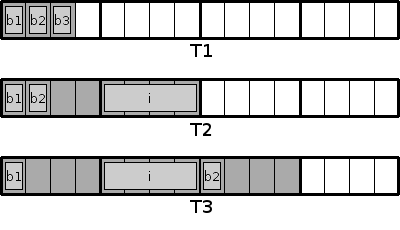
Die grau gefärbten Bereiche geben den belegten Speicher an. Sobald ein größerer Datentyp verwendet wird, wie in diesem Beispiel ein (32-Bit-)Integer, findet ein Padding auf die Größe dieses Datentyps statt.3 Das wird vor allem beim UDT T3 deutlich: Auch der Platz hinter dem letzten einzelnen Byte wird auf vier Bytes aufgefüllt.
Das Standard-Paddingverhalten kann durch das Schlüsselwort FIELD verändert werden. Sie können das Padding dadurch allerdings nur verkleinern, nicht vergrößern.
TYPE T4 FIELD=1 AS BYTE b1 AS INTEGER i AS BYTE b2 END TYPE TYPE T5 FIELD=2 AS BYTE b1 AS INTEGER i AS BYTE b2 END TYPE TYPE T6 FIELD=2 AS BYTE b1, b2 AS INTEGER i END TYPE PRINT "UDT", "SIZEOF", "Offset 1", "Offset 2", "Offset 3" PRINT "T4", SIZEOF(T4), OFFSETOF(T4, b1), OFFSETOF(T4, i), OFFSETOF(T4, b2) PRINT "T5", SIZEOF(T5), OFFSETOF(T5, b1), OFFSETOF(T5, i), OFFSETOF(T5, b2) PRINT "T6", SIZEOF(T6), OFFSETOF(T6, b1), OFFSETOF(T6, b2), OFFSETOF(T6, i) SLEEP
UDT SIZEOF Offset 1 Offset 2 Offset 3
T4 6 0 1 5
T5 8 0 2 6
T6 6 0 1 2T5 unterscheidet sich von T4 durch das größere Padding. T6 verwendet zwar dasselbe Padding wie T5, belegt aber trotzdem weniger Speicher, da die Attribute platzsparender angeordnet sind. Schematisch dargestellt sieht das so aus:
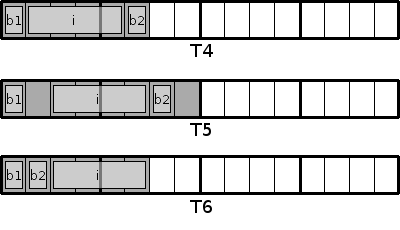
Durch eine geringere Ausdehnung wird Speicherplatz gespart, Sie sehen jedoch, dass das Integer nun nicht mehr eine vollständige Integer-Stelle belegt, sondern sich über eine der Grenzen erstreckt. Der Bonus bei der Zugriffgeschwindigkeit geht damit verloren. In der Regel wird FIELD nur verwendet, um eine Kompatibilität zu externen Bibliotheken herzustellen. Wenn dort die Speicherverwaltung anders abläuft als unter FreeBASIC, kommt es unweigerlich zu Problemen. Ansonsten lohnt sich der Einsatz von Padding in der Regel nicht — sinnvoller ist es, die Attribute so in der Deklaration anzuordnen, dass die durch das Padding entstehenden Lücken nicht unnötig groß werden.
|
|
Unterschiede zu QuickBASIC: In QuickBASIC existiert kein Padding. Die Feldbreite beträgt dort immer 1 Byte. Das muss vor allem dann beachtet werden, wenn Sie in FreeBASIC Daten einlesen wollen, die mit QuickBASIC erstellt wurden. |
7.4 Bitfelder
Manchmal benötigt man deutlich kleinere Datentypen als ein BYTE. In einem Formular mit mehreren Kontrollkästchen werden eine Reihe von Variablen benötigt, die lediglich den Zustand „angeklickt“ oder „nicht angeklickt“ speichern müssen. Es reicht also jeweils ein Bit pro Kontrollkästchen.
So etwas lässt sich über Bitfelder lösen. Dazu wird eine Ganzzahl-Variable in eine Anzahl von einzelnen Bits aufgeteilt. Wir erinnern uns: Jedes Bit kann zwei Zustände annehmen (1 oder 0). Mit zwei Bits sind dann 22=4 Zustände möglich, mit drei Bits 23=8 usw. Eine solche Aufsplittung ist nur innerhalb eines UDTs erlaubt. Dazu wird hinter dem Attributnamen ein Doppelpunkt geschrieben, gefolgt von der gewünschten Bit-Zahl.
TYPE TFormular AS INTEGER button1 : 1 button2 : 1 AS INTEGER ' alternative Schreibweise AS INTEGER radio : 3 END TYPE
Hier werden drei Attribute deklariert, von denen zwei ein Bit lang sind und eines drei Bit lang. Das bedeutet: button1 und button2 können jeweils nur zwei verschiedene Werte annehmen (0 oder 1), radio dagegen acht (von 0 bis 7). Wenn Sie einem Attribut einen zu großen Wert zuweisen wollen, wird dieser automatisch „zurechtgestutzt“. Wenn Sie also z. B. in radio den Wert 10 speichern wollen (binär 1010), werden nur die hinteren drei Bit verwendet und der Rest verworfen — gespeichert wird damit der Wert 2. Abgesehen davon verhalten sich Bitfelder jedoch ganz genauso wie andere Attribute.
Es sollte noch ergänzt werden, dass die gewählte Bitzahl nicht größer sein kann als die Bitzahl des zugrunde liegenden Datentyps. Es können z. B. keine 9 Bit eines BYTE verwendet werden oder 33 Bit eines 32-Bit-Integers (sehr wohl aber eines 64-Bit-Integers). Außerdem wird LONGINT nur in der 64-Bit-Version des Compilers unterstützt.
Des Weiteren wird ein UDT immer vollständige Bytes als Speicherplatz belegen. Ein UDT mit einem einzigen Bitfeld-Attribut wird keine Speicherersparnis mit sich bringen. Selbst wenn das Attribut nur ein einziges Bit belegt, wird die Größe des UDTs durch die Größe des gewählten Datentyps festgelegt. Eine Platzersparnis tritt erst ein, wenn der Speicherplatz des gewählten Datentyps auf mehrere Attribute aufgeteilt wird.
7.5 UNIONs
Eine UNION ist ein UDT, dessen Elemente sich dieselbe Speicheradresse teilen. Abhängig vom Einsatzbereich kann der Inhalt der Speicherstelle auf verschiedene Arten interpretiert werden, eine Änderung des Inhalts wirkt sich aber natürlich auch auf die anderen Elemente aus.
UNION testunion AS BYTE byteVar AS SHORT shortVar END UNION DIM AS testunion wert wert.shortVar = 26 PRINT wert.shortVar, wert.byteVar wert.shortVar = 260 PRINT wert.shortVar, wert.byteVar wert.byteVar = 3 PRINT wert.shortVar, wert.byteVar SLEEP
26 26
260 4
259 3wert.byteVar interpretiert den Speicherinhalt nur als BYTE, wodurch sich der ausgegebene Wert 4 ergibt. In diesem Fall hätte natürlich eine einfache Typumwandlung von SHORT zu BYTE ausgereicht. In den Zeilen 14 und 15 sieht man aber, dass eine Änderung von wert.byteVAR nur das erste Byte von wert.shortVar verändert und das andere Byte unverändert lässt.
-
26besitzt den Binärwert00000000 00011010. Das höherwertige Byte ist0, weshalbwert.byteVarundwert.shortVardenselben Wert ausgeben. -
260besitzt den Binärwert00000001 00000100. Das niedere Byte besitzt den Wert4, der vonwert.byteVarausgegeben wird. -
Bei der dritten Änderung wird in das niedere Byte der Dezimalwert
3bzw. der Binärwert00000011gelegt. Im Speicher liegt nun der Binärwert00000001 00000011bzw. als Dezimalwert259. Etwas genauer werden wir auf das Binärsystem in Kapitel 10.2.3 eingehen.
Gern verwendet wird UNION innerhalb eines UDTs, das für mehrere Zwecke eingesetzt werden soll. Elemente, die nicht gleichzeitig zum Einsatz kommen, können sich eine Speicherstelle teilen, da sie sich ja nicht gegenseitig in die Quere kommen können. FreeBASIC selbst nutzt das bei der Deklaration von Grafik-Headern. Die alten QuickBASIC-Header sind folgendermaßen aufgebaut:
TYPE _OLD_HEADER FIELD = 1 bpp : 3 AS USHORT width : 13 AS USHORT height AS USHORT END TYPE
Für die Ansprüche von FreeBASIC ist eine Beschränkung auf 8191 Pixel Bildbreite nicht unbedingt wünschenswert. Deswegen wurde ein neues Header-Format gewählt, das zusätzlich noch Platz für weitere Informationen bietet. Da aber auch die im alten QuickBASIC-Format gespeicherten Bilder noch unterstützt werden sollen, wurde der neue Header folgendermaßen definiert:
TYPE Image FIELD = 1 UNION old AS _OLD_HEADER type AS ULONG END UNION bpp AS LONG width AS ULONG height AS ULONG pitch AS ULONG _reserved(1 to 12) AS UBYTE END TYPE
type gibt die Versionsnummer des Headers zurück; beim neuen Headerformat ist das immer 7. Der alte Header kann dagegen niemals den Wert 7 annehmen. Abhängig von type kann FreeBASIC also entscheiden, ob die weiteren Daten nach dem alten oder neuen Header-Format interpretiert werden müssen.
Eine innerhalb von TYPE-Deklarationen verwendete UNION darf keinen eigenen Bezeichner erhalten. Stattdessen werden die UNION-Attribute direkt über den Bezeichner des UDTs angesprochen, also z. B. im oben stehenden Grafik-Header folgendermaßen:
DIM AS Image meinBild IF meinBild.type <> 7 THEN PRINT "Der alte Header wird verwendet."
Ein weiteres Beispiel direkt aus dem FreeBASIC-internen Fundus stellt das UDT Event dar, das von der Funktion SCREENEVENT() verwendet wird. Wir werden uns mit diesem Befehl in [KapGrafikScreenevent] genauer beschäftigen. Kurz gesagt geht es um die Abfrage bestimmter Ereignisse wie Mausbewegung, Tastendruck, Betreten oder Verlassen des Grafikfensters usw. Dabei liefern die verschiedenen Ereignisse teils unterschiedliche Informationen — z. B. ist es für die Mausbewegung wichtig, wohin die Maus bewegt wurde, während ein Tastendruck die gedrückte Taste zurückgeben soll. Da weder die Maus einen Tastendruck zurückgibt noch die Tastatur eine Mausposition, können sich beide Informationen den Speicherbereich teilen.
7.6 Fragen zum Kapitel
Die folgenden Programmieraufgaben bauen aufeinander auf. Sie können also mit dem Ergebnis aus Aufgabe 1 in Aufgabe 2 weiterarbeiten und mit diesem Ergebnis in Aufgabe 3.
-
Als Einzelhandelsunternehmen wollen Sie Ihre Produkte katalogisieren. Erstellen Sie ein UDT, in dem Sie die Informationen eines Produktes speichern können: Name, Einkaufspreis, Verkaufspreis und vorhandene Stückzahl. Wählen Sie jeweils passende Datentypen.
-
Lassen Sie den Benutzer über
INPUTfür zwei Produkte die Attributwerte eingeben. Wenn die Eingabe unsinnig ist, soll eine Warnung ausgegeben werden — beispielsweise soll der Verkaufspreis nicht negativ sein und nicht unterhalb des Einkaufspreises liegen. -
Geben Sie für die beiden eingegebenen Produkte jeweils den Namen und den zu erwartenden Gewinn pro verkauftes Stück aus (der Gewinn berechnet sich aus dem Unterschied zwischen Verkaufs- und Einkaufspreis).
Fußnoten:
1) In [KapOOP] werden wir lernen, dass es zwei Arten von Mitgliedern gibt: Die Attribute (Member-Variablen) und die Methoden (Member-Funktionen).
2) Das funktioniert nur, wenn alle Attribute eine feste Länge besitzen, also u. a. keine Strings variabler Länge eingesetzt werden.
3) Genauer gesagt wird das Standard-Padding durch den größten Datentyp festgelegt, beträgt aber höchstens 4 (unter 32-Bit x86 Linux/BSD) bzw. 8 (bei allen anderen Systemen).